Simula Research Laboratory /
Center for Resilient Networks and Applications /
NorNet
Homepage of Thomas Dreibholz /
Thomas Dreibholz's Flow Routing Project Page
Simula Research Laboratory /
Center for Resilient Networks and Applications /
NorNet
Homepage of Thomas Dreibholz /
Thomas Dreibholz's Flow Routing Project Page

This website has been refurbished with up-to-date Publications and Standardisation sections.
Updated Internet Drafts in the Publications section.
BibTeX entries have been added to the Publications section.
Updated the drafts in the Standardisation section.
A new journal article has been added to the Publications section.
The Internet Drafts in the Standardisation section have been updated.
The slides of the FGCN 2008 talk have been added to the Publications section.
This project is still alive! There are two new research papers on the QoS Device in the Publications section! Furthermore, the Standardisation section has been updated with the latest IPv4 Flowlabel drafts.
The Internet was originally designed as a best effort network to support simple applications like electronic mail and file transfers via low-speed links. Since high-speed gigabit backbones have become widespread within the last few years and high-speed links are even available for home-users in the form of DSL (digital subscriber line), new multimedia applications like audio on demand (AoD), video on demand (VoD), audio/video conferences and Internet telephony are possible. But while a best effort delivery is sufficient for classical TCP/IP-based applications like web browsing, the new applications require strict delivery guarantees. For example, the perceptual quality of a video conference may be poor when it does not get a constant bitrate of 2 Mbit/s.

A Network with Flow Routing – Click here to show picture in full size!
In the early ages of the Internet memory had been scarce and extremely expensive. Therefore, routing had been realized on a per-packed basis. While this scheme achieved a cost advantage in reducing the amount of memory required in routers, it has become a severe problem in today's routers. Nowadays, memory is quite inexpensive – therefore, per-packet routing does not achieve a significant cost advantage – but networks are very fast. That is, a tremendous amount of CPU power is needed to efficiently route packets at speeds of multiple gigabits per second. Flow-state aware routing can significantly reduce this effort: instead of making a routing decision for every packet, a router memorizes flow identities and only makes a routing decision once for each flow. Maintaining flow tables containing even millions of flows is significantly cheaper than routing each packet (routing tables for BGP routers can grow very large!), resulting in flow-state aware routing becoming even less expensive than classical per-packet routing. Flow-routing may be implemented incrementally, that is flow-based routers can co-exist with classical routers in the same network as shown in the figure above.
Flow-state aware routing not only offers the advantage of inexpensive routing, it also makes it possible to implement Quality of Service (QoS) mechanisms. The goal of our project is a simple and efficient QoS protocol to provide QoS assurances to certain flows, which can be implemented for flow routers (and also for classical, packet-based routers with some additional effort). A key assumption for our QoS concept – based on observations by IP broadband providers – is that service providers (e.g. audio and video media libraries) are connected via a high-speed internetwork to the access providers of the customers as shown here:
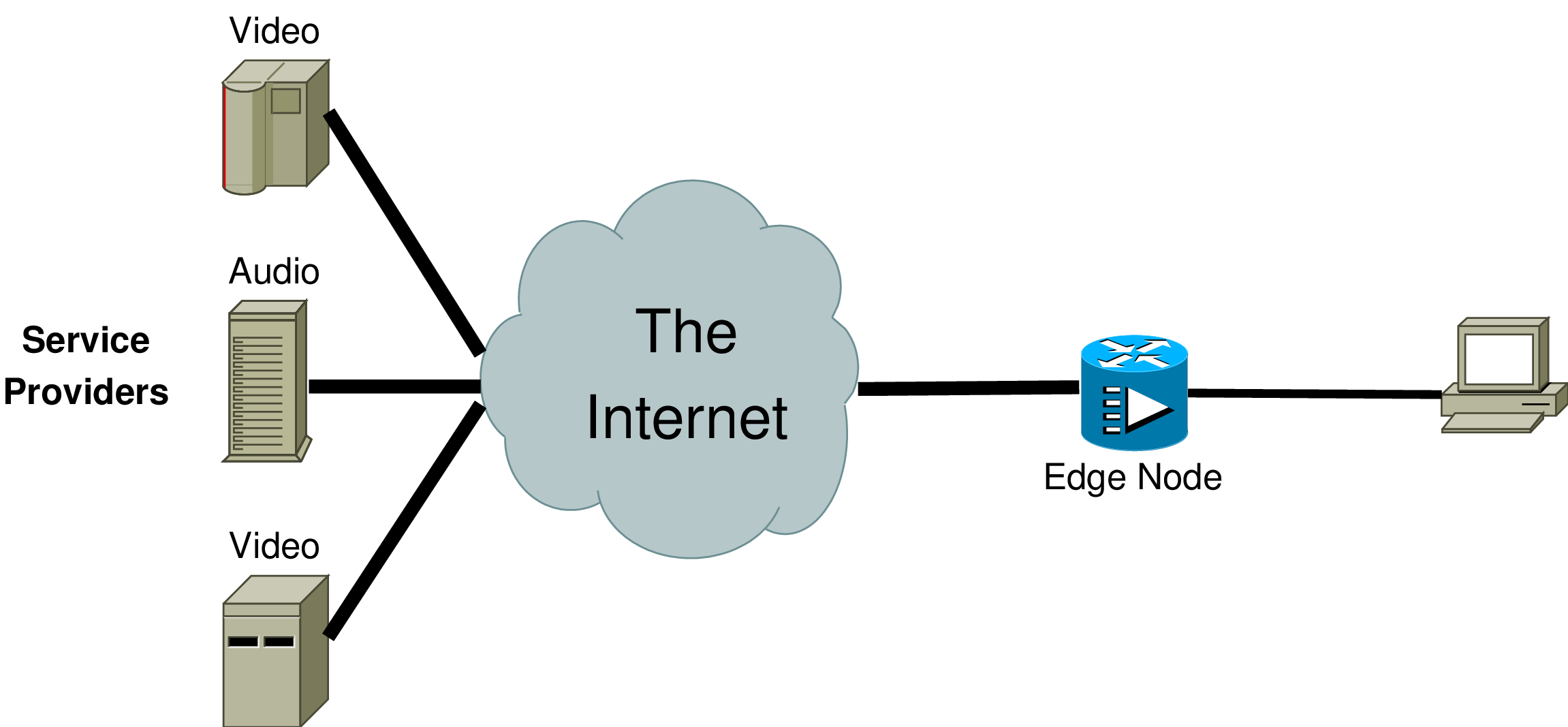
An Example Scenario – Click here to show picture in full size!
The customers may be connected via an edge node to Access Providers by e.g. DSL links, TV cable, Wireless LAN (IEEE 802.11), UMTS or ATM. Different service providers may simultaneously deliver content to a single customer. Core bandwidth is usually over-provided, therefore, it is further assumed that the link to the customer becomes the main bottleneck of the system and the edge node is the place where congestion occurs.
As long as the user does not request more media flows than available link bandwidth, there should be no problem. But let us consider the following scenario as shown in the figure here:
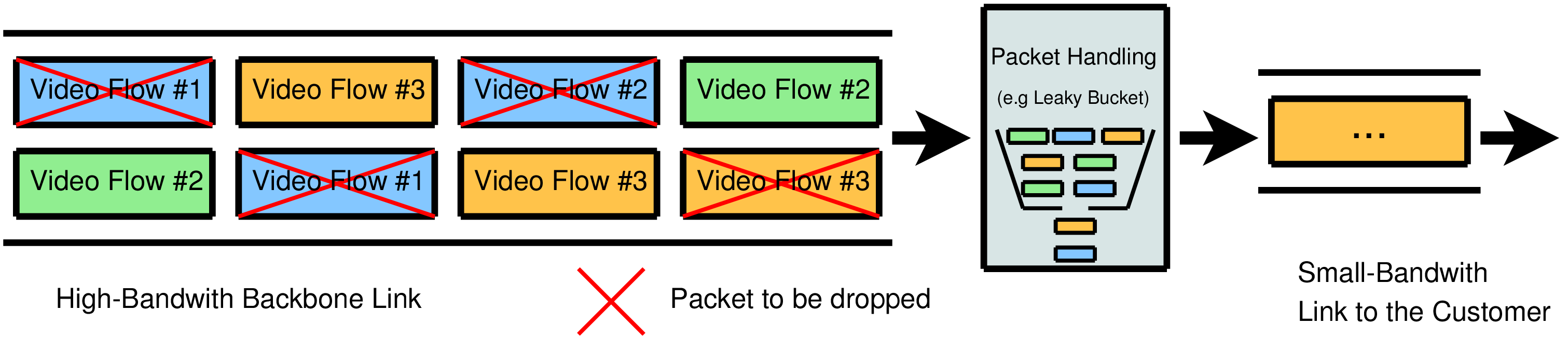
An Overload Example – Click here to show picture in full size!
One family member requests a sports video at 5 Mbit/s, another one requests a soap opera at 3 Mbit/s and yet another requests an action video at 5 Mbit/s via a single 10 Mbit/s link. This is a situation where packet loss is likely to occur. Since all flows have equal priority, the packet loss is likely to affect all flows. It is possible that the quality reduction is so severe that all flows are of unacceptable quality. Clearly, an edge node that was able to apply an intelligent discard policy, focusing loss on a single (or as few as possible) flows, would minimise disruption to the total number of flows (see [Smith91]).
The basic principle may be illustrated using the simplest scenario: all content is constant bitrate. Assume that the customer adds new flows one at a time with some short interval (e.g. some seconds) before the next flow is added. Then congestion happens through the "last straw" (i.e. "Its the last straw which breaks the camel's back" – Proverb) principle. In other words, there is no congestion until a flow is added which takes the combined bitrate above the capacity available for that customer. It is easy to see that by simply deleting the packets of this latest flow, congestion would be removed. This suggests, that the QoS protocol needs to memorise the identity of the latest flow and be prepared to delete the packets of this flow. Then, it would be possible to protect the remaining flows from congestion.
We can now extend this scenario to include variable bitrate flows; here, the QoS protocol needs to memorize the last r flows. When congestion occurs, the device still tries to delete the packets of the latest flow but is prepared to drop packets of the other r-1 flows if congestion persists. Further complexity is added as we move from a strictly "last flow suffers" world into a policy-based world where the latest flow is not necessarily the one that will be targeted.
Having set out the principle of the device, we can now describe the functionality.
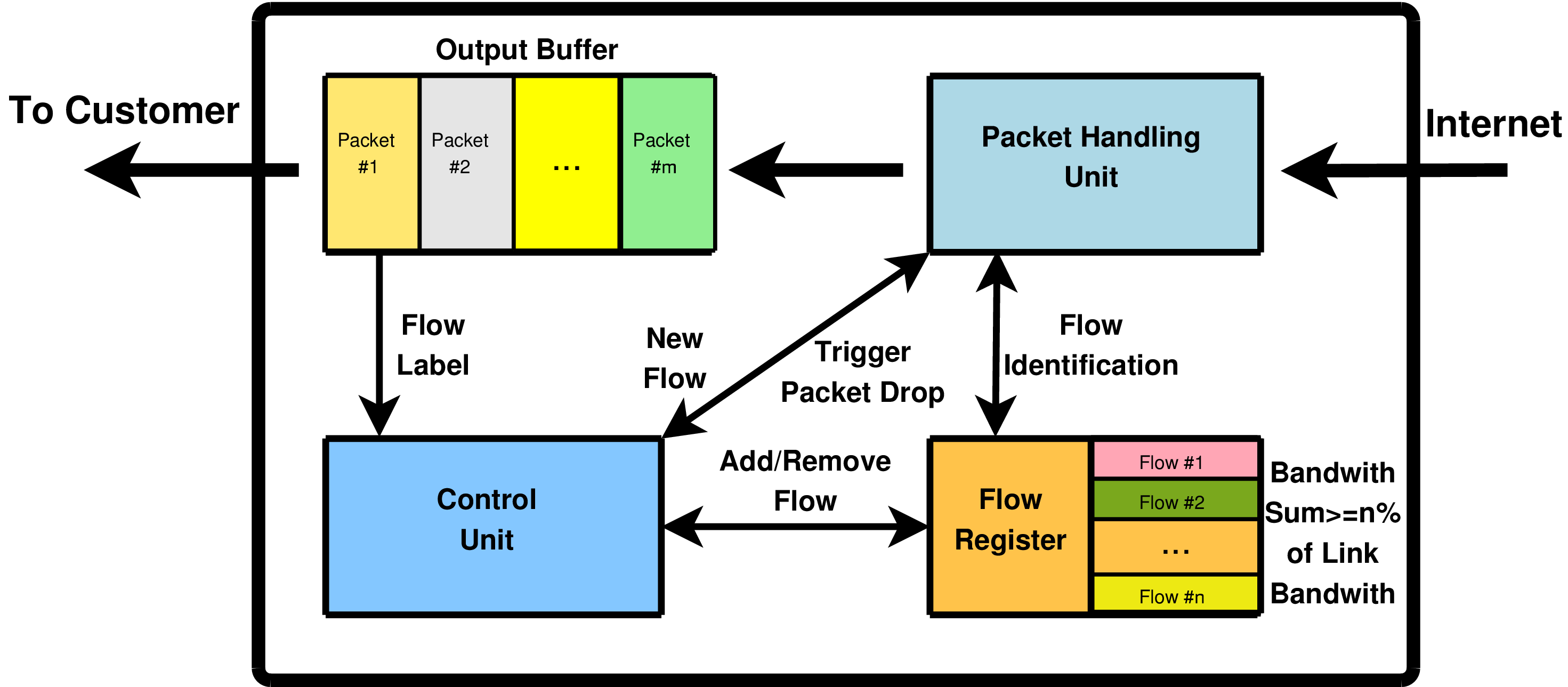
The Main Functions of Our QoS Protocol – Click here to show picture in full size!
As shown here, the device contains the following functions for each of its customer links:
The Output Buffer holds the data to be sent via the link to the customer. This is necessary to cope with bursty traffic. Its current fill level is reported to the Control Logic. Note, the set of customer buffers need not be separate, they can be implemented e.g. using a global memory area.
The Flow Register keeps a list of flows that are the focus of packet discard (the so called Drop Window, see below).
The Packet Handling Unit receives incoming packets and identifies whether they belong to flows which are currently the focus of packet discard by using the Flow Register. It also applies a discard function to the packets. That is, it drops packets of flows selected by the Control Logic for focused packet discard.
Flows are added to and removed from the Flow Register by the Control Logic. Furthermore, it controls the packet drop behaviour by examining the Output Buffer's load level. In case of congestion, it decides which flows are the focus of packet dropping and triggers the packet dropping by the Packet Handling Unit.
A key assumption is that service providers (e.g. audio and video media libraries) are connected via a high-speed internetwork to the access providers of the customers as shown here: We propose that at start up a new flow begins with the sending of a "Start Packet", which contains all information necessary to identify the packets of the flow (e.g. source and destination addresses, flow label or port numbers), a Rate Advisory, that is the (estimated) peak rate of the flow, a policy field which contains a policy for the flow (e.g. to move it directly to the Guaranteed Area, see below), a priority field that contains the priority of the flow and finally a sub-components field that contains information about different layers of the flow (so called layered transmission, see [Dre01]). Notice also that this device fits with the connection-less paradigm in that the sources are only required to transmit a Start Packet and then, without waiting further, start to transmit their data. There is no negotiation, unlike classical RSVP.
When the edge node receives a Start Packet for a new flow, the Control Logic adds the flow to the Flow Register Policies allow a refinement of this behaviour.. This register contains the identities of all flows that are in the Drop Window, and are a potential focus of packet discard in the case of congestion. The Drop Window has a limited number of entries (configured by the administrator) and the sum of all flows' Rate Advisories within the window should be >= N% of the link bandwidth.
With the duration of time, flows gradually move through the Drop Window into the Guaranteed Area. This movement within the Drop Window actually consists of a re-classification of flows so that they become less likely to be targeted. The default policy is that the latest flow will be the subject of immediate discards in the event of congestion and only when discards on this flow fail to reduce congestion will the additional flows be targeted.
After arriving in the Guaranteed Area, flows will not be the focus of packet discard any longer, except in cases of rare and very extreme congestion where the amount of packets necessary to drop exceeds the amount of packets currently sent by flows within the Drop Window. (The fact that up to N% of the link bandwidth is available for discard should make such an action very rare.) Even in these circumstances, the Guaranteed Area is not subjected to random losses. Rather, the device randomly selects by choosing a packet from the Output Buffer and obtaining its flow identity. one new flow at a time from the Guaranteed Area and adds it temporarily to the Drop Window, thereby increasing the packets available for discard to > N%.
Returning to the description of the normal movement of flows through the Drop Window to the Guaranteed Area, the default policy is to move the flow that has been within the Drop Window for the longest time into the Guaranteed Area, when the remaining additional flows themselves constitute >= N% of the link bandwidth. Other useful policies are e.g. to move video conferences first.
Note that it is a special property of our device that it is not necessary to save the identities of flows within the Guaranteed Area. It is implicitly assumed that all packets not belonging to flows of the Drop Window are flows of the Guaranteed Area. Therefore, only a constant space is required for each customer link's Drop Window; this significantly improves the device's scalability. Normally, flows within the Drop Window are just overwritten by new flows; however the device also has a mechanism, based on time and/or packet count, to remove flows from the window. This property ensures efficiency and scalability.
As stated, the flows within the Drop Window are the focus of packet discard in case of congestion. The Control Logic detects congestion by monitoring the buffer fill level. If the congestion reaches a certain configured threshold, it triggers packet discard by the Packet Handling unit. This is applied to all packets of (usually) the latest flow added to the Drop Window. Furthermore, the source and receiver of the flow are notified about the congestion by a Congestion Notification message in the form of an Alarm Packet. If congestion continues after this action and the buffer fill level reaches a second threshold, then the Control Logic instructs the Packet Handling unit to begin discarding on all the other flows in the Drop Window. Again alarm messages are sent to the sources and receivers. Since the Rate Advisory sum of all flows in the Drop Window is <= N of the link bandwidth, there should be sufficient droppable packets. Only in some rare cases of extreme congestion (for example by a malicious user), may it be necessary to drop packets from flows within the Guaranteed Area.
Beside simplicity, efficiency and scalability, our described edge node further provides the following advantages compared to RSVP: a guarantee is provided for the admitted flows except under extreme and very rare traffic conditions. Selected flows will be targeted for packet loss, other flows can continue without any loss or undesirable packet delays. It is possible to admit flows without knowing the remaining capacity of the link and admit variable bitrate flows without being constrained to accept only a set of flows whose peak rates are less than the available capacity, but it is not necessary to keep active/ceased state information on admitted flows. The admission of flows does not require a suspension of higher-level session control protocols; a sender is only required to send a Start Packet.
The complete BibTeX references in a single file can be found here!
Dreibholz, Thomas: ``An IPv4 Flowlabel Option´´ (TXT, 18 KiB, 🇬🇧), Internet Draft draft-dreibholz-ipv4-flowlabel-39, IETF, Individual Submission, March 30, 2024, [BibTeX, XML].
Abstract: This draft defines an IPv4 option containing a flowlabel that is compatible to IPv6. It is required for simplified usage of IntServ and interoperability with IPv6.
URL: https://tools.ietf.org/id/draft-dreibholz-ipv4-flowlabel-39.txt
MD5: ba75213ffdff7f8f46f501ad6eb29d11
Zhu, Wenyu; Dreibholz, Thomas; Rathgeb, Erwin Paul and Zhou, Xing: ``A Scalable QoS Device for Broadband Access to Multimedia Services´´ (PDF, 1081 KiB, 🇬🇧), in SERSC International Journal of Multimedia and Ubiquitous Engineering (IJMUE), vol. 4, no. 2, pp. 157–172, ISSN 1975-0080, April 30, 2009, [BibTeX, XML].
Keywords: Quality of Service (QoS), Broadband Internet, Flow Routing, Multimedia, Intelligent Packet Discard
Abstract: Nowadays, an increasing number of users gets high-speed broadband access to the Internet. These broadband connections make new multimedia applications possible. However, such applications also introduce new Quality of Service (QoS) requirements to the network. Particularly, they require an assured bandwidth even in the case of network overload. The network itself has to provide such bandwidth assurances. This article introduces our concept of a novel network QoS device being located in network edge nodes. It provides a solution for relaxed QoS guarantees to certain flows on a congested link by focussing packet discard on selected flows. However, unlike for IntServ solutions like RSVP, our approach only requires minimal signalling and therefore provides both efficiency and scalability. We furthermore provide a quantitative performance evaluation of our QoS device by using simulations.
URL: https://gvpress.com/journals/IJMUE/vol4_no2/14.pdf
MD5: 3a8837e5ef699ddff971bcdfbf98b84b
Zhu, Wenyu; Dreibholz, Thomas; Rathgeb, Erwin Paul and Zhou, Xing: ``A Scalable QoS Device for Broadband Access to Multimedia Services´´ (PDF, 509 KiB, 🇬🇧), in Proceedings of the IEEE International Conference on Future Generation Communication and Networking (FGCN), vol. 1, pp. 343–348, DOI 10.1109/FGCN.2008.124, ISBN 978-0-7695-3431-2, Sanya, Hainan/People's Republic of China, December 13, 2008, [BibTeX, XML].
Keywords: Quality of Service (QoS), Broadband Internet, Flow Routing, Multimedia, Intelligent Packet Discard
Abstract: This paper presents the performance evaluation of a novel network device being located in network edge nodes. It provides a solution for relaxed QoS guarantees to certain flows on a congested link by focussing packet discard on selected flows. However, unlike IntServ solutions – e.g. RSVP – our approach only requires minimal signalling and therefore provides both efficiency and scalability. In this paper, we first describe the ideas of our QoS device and then provide a simulative performance analysis for different multimedia flow scenarios.
URL: https://www.wiwi.uni-due.de/fileadmin/fileupload/I-TDR/FlowRouting/Paper/FGCN2008.pdf
MD5: 4aeb2680d2d15cb85f53961ff16c707c
Zhu, Wenyu; Dreibholz, Thomas and Rathgeb, Erwin Paul: ``Analysis and Evaluation of a Scalable QoS Device for Broadband Access to Multimedia Services´´ (PDF, 166 KiB, 🇬🇧), in Proceedings of the 33rd IEEE Conference on Local Computer Networks (LCN), pp. 504–505, DOI 10.1109/LCN.2008.4664212, ISBN 978-1-4244-2413-9, Montréal, Québec/Canada, October 15, 2008, [BibTeX, XML].
Keywords: Quality of Service (QoS), Broadband Internet, Flow Routing, Multimedia, Intelligent Packet Discard
Abstract: This paper presents the initial evaluation of a novel network device being located in edge nodes. It provides relaxed QoS guarantees to certain flows on a congested link by focussing packet discard on selected flows. In contrast to classical IntServ solutions, our approach requires minimal signalling and therefore provides both efficiency and scalability. In this paper, we first describe the ideas of our QoS device and then provide first results of our ongoing simulative performance evaluation and optimization.
URL: https://www.wiwi.uni-due.de/fileadmin/fileupload/I-TDR/FlowRouting/Paper/LCN2008-FlowRouting.pdf
MD5: 4b24ce40f15989ca57ccb44bdbdf4d82
Dreibholz, Thomas; IJsselmuiden, Avril J. and Adams, John L.: ``An Advanced QoS Protocol for Mass Content´´ (PDF, 113 KiB, 🇬🇧), in Proceedings of the IEEE Conference on Local Computer Networks (LCN) 30th Anniversary, pp. 517–518, DOI 10.1109/LCN.2005.25, ISBN 0-7695-2421-4, Sydney, New South Wales/Australia, November 17, 2005, [BibTeX, XML].
Keywords: Quality of Service (QoS), Signalling Protocols, Telecommunication Congestion Control, Telecommunication Traffic
Abstract: This paper presents a novel network device being located in network edge nodes. It provides a solution for QoS guarantees to certain flows on a congested link by focussing packet discard on selected flows. Unlike IntServ solutions like RSVP, our approach only requires minimal signalling and provides both efficiency and scalability. In this paper, we first describe the ideas of our QoS device and then provide first results from a fast-track simulation model implementing a lightweight version of our approach.
URL: https://www.wiwi.uni-due.de/fileadmin/fileupload/I-TDR/FlowRouting/Paper/LCN2005-EdgeDevice.pdf
MD5: 081882106105904aa7f496def9022c4e
Dreibholz, Thomas; IJsselmuiden, Avril J. and Adams, John L.: ``Simulation of an Advanced QoS Protocol for Mass Content´´ (PDF, 248 KiB, 🇬🇧), in Proceedings of the 2nd International Conference on Performance Modelling and Evaluation of Heterogeneous Networks (HET-NETs), Ikley, West Yorkshire/United Kingdom, July 26, 2004, [BibTeX, XML].
Keywords: Quality of Service (QoS), Signalling Protocols, Telecommunication Congestion Control, Telecommunication Traffic
Abstract: This paper describes a new network device to be located in network edge nodes. The device can deal with congestion conditions that may arise when, for example, a home or SME customer requests too many simultaneous flows to be forwarded down a DSL link or other access technology. It provides a solution to guaranteeing certain flows that are forwarded along one or more congested links, by making others (typically the latest flow, or another flow selected because of policy reasons), the subject of focused packet discards. The functionality of the device is described, and results from a fast-track simulation model implementing a lightweight version of the device, developed in LISP, are presented here.
URL: https://www.wiwi.uni-due.de/fileadmin/fileupload/I-TDR/FlowRouting/Paper/HET-NET2004-Paper.pdf
MD5: 1e3573935ab2e0b86e9d3288dbc7109d
Dreibholz, Thomas; Smith, Avril J. and Adams, John L.: ``Realizing a Scalable Edge Device to Meet QoS Requirements for Real-Time Content Delivered to IP Broadband Customers´´ (PDF, 112 KiB, 🇬🇧), in Proceedings of the 10th IEEE International Conference on Telecommunications (ICT), vol. 2, pp. 1133–1139, DOI 10.1109/ICTEL.2003.1191595, ISBN 0-7803-7661-7, Papeete/French Polynesia, February 26, 2003, [BibTeX, XML].
Keywords: Quality of Service (QoS), Bandwidth Guarantee, Admission Control, Congestion Control, Intelligent Packet Dropping, Edge Node, Security, Implementation Considerations
Abstract: With DSL technology becoming widespread, more and more customers have access to high-speed Internet backbones. Such links not only speed up classical best effort applications but also make new applications like video and audio on demand possible. Unlike best effort applications, these new applications have more requirements for network quality of service, especially an assured bandwidth. Under the assumption that the link to the customer is the main bottleneck, this paper presents a new simple, scalable edge node approach that has been developed in a cooperation between the University of Essen and British Telecom (BT). It provides a solution to guaranteeing certain flows, while making others the subject of focused packet discards. While the performance aspect of this new device is currently under research, this paper lays its focus on implementability and especially provides a security concept.
URL: https://www.wiwi.uni-due.de/fileadmin/fileupload/I-TDR/FlowRouting/Paper/EdgeDevice-Paper.pdf
MD5: 7c37d41dd417062ba4fd17063d846939
Dreibholz, Thomas: ``Management of Layered Variable Bitrate Multimedia Streams over DiffServ with Apriori Knowledge´´ (PDF, 60591 KiB, 🇬🇧), Masters Thesis, University of Bonn, Institute for Computer Science, URN urn:nbn:de:hbz:464-20120416-095753-8, February 20, 2001, [BibTeX, XML].
Keywords: Multimedia, Quality of Service, Layered Transmission, DiffServ, A Priori Knowledge
Abstract: The Internet is developing with a very high speed. Just a few years ago, its main applications were file transfer and e-mail access, all based on the best effort TCP/IP service over quite slow links. With the quickly growing deployment of high-speed Internet accesses, there is a growing demand for also using the Internet in application scenarios like real-time multimedia streaming, particularly for audio and video on demand services. However, such multimedia applications do not only require sufficient bandwidth. They have stricter quality of service demands, like e.g. an upper bound on the transfer delay to ensure interactivity for their users. In the context of this thesis, a system for the cost-efficient transfer of variable bitrate multimedia streams over Differentiated Services (DiffServ) is presented and evaluated. This system supports layered transmission, i.e. streams may be partitioned into sub-streams denoted as layers (e.g. a video layer and an audio layer). Distinct layers may have different priorities as well as quality of service requirements and may therefore use different DiffServ classes for data transmission. Also, the streams may be scalable, i.e. the quality of the transferred media may be decreased in order to reduce the bandwidth requirements when bandwidth becomes scarce. Particularly, the system makes use of the fact that media files in e.g. a video on demand library can be analyzed a priorily. The information that is computed during the offline analysis is used to realize a dynamic and cost-efficient transport of layer data over different DiffServ classes. Furthermore, the system applies an adaptive buffering to smooth the flows – in order to save bandwidth – while also taking care of the delay constraints.
URL: https://duepublico.uni-duisburg-essen.de/servlets/DerivateServlet/Derivate-29936/Dre2001.pdf
MD5: 479cc723184d88dbce6864ab93f9b6c0
Dreibholz, Thomas; Selzer, Jan and Vey, Simon: ``Echtzeit-Audioübertragung mit QoS-Management in einem DiffServ-Szenario´´ (PDF, 4322 KiB, 🇩🇪), Projektseminararbeit, Universität Bonn, Institut für Informatik, August 14, 2000, [BibTeX, XML].
Keywords: Quality of Service (QoS), Real-Time, Audio, DiffServ, RTP Audio
URL: https://www.nntb.no/~dreibh/rn/DSV00.pdf
MD5: 9aed1f5be5c1badcd41efe3e414614c0
The complete BibTeX references in a single file can be found here!
Dreibholz, Thomas: ``An IPv4 Flowlabel Option´´ (TXT, 18 KiB, 🇬🇧), Internet Draft draft-dreibholz-ipv4-flowlabel-39, IETF, Individual Submission, March 30, 2024, [BibTeX, XML].
Previous versions: draft-dreibholz-ipv4-flowlabel-38, 37, 36, 35, 34, 33, 32, 31, 30, 29, 28, 27, 26, 25, 24, 23, 22, 21, 20, 19, 18, 17, 16, 15, 14, 13, 12, 11, 10, 09, 08, 07, 06, 05, 04, 03, 02, 01, 00.
Abstract: This draft defines an IPv4 option containing a flowlabel that is compatible to IPv6. It is required for simplified usage of IntServ and interoperability with IPv6.
URL: https://tools.ietf.org/id/draft-dreibholz-ipv4-flowlabel-39.txt
MD5: ba75213ffdff7f8f46f501ad6eb29d11
Smith, Avril J. and Adams, John L.: ``Description of the QoS device´´ (🇬🇧), Contribution, ITU-T, Geneva/Switzerland, December 2004, [BibTeX, XML].
Smith, Avril J. and Adams, John L.: ``Delivery of Assured QoS Content in NGNs´´ (🇬🇧), British Telecom Contribution D-,Q4,6,10,11,16,SG13, ITU-T, Geneva/Switzerland, February 2004, [BibTeX, XML].
Smith, Avril J. and Adams, John L.: ``Proposal for a New IP Transfer Capability and Future QoS Studies´´ (🇬🇧), no. D-,Q4,6,10,11,16,SG13, ITU-T, Geneva/Switzerland, February 2004, [BibTeX, XML].
Smith, Avril J. and Adams, John L.: ``Delivering QoS from Remote Content Providers´´ (🇬🇧), British Telecom Contribution TISPAN 01(03)TD132, ETSI, Sophia-Antipolis/France, September 2003, [BibTeX, XML].
Smith, Avril J. and Adams, John L.: ``Packet Discard Control for Broadband Services´´ (PDF, 803 KiB, 🇬🇧), no. EP 01 30 5209, British Telecom, June 2002, [BibTeX, XML].
URL: https://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.13.927&rep=rep1&type=pdf
MD5: b46e9a2fad370358756adbafa7230199
Adams, John L. and Smith, Avril J.: ``A New QoS Mechanism for Mass-Market Broadband´´ (🇬🇧), British Telecom Contribution D184, Q4, SG13, ITU-T, Geneva/Switzerland, January 2002, [BibTeX, XML].
Adams, John L. and Smith, Avril J.: ``A New QoS Mechanism for Mass-Market Broadband´´ (TXT, 30 KiB, 🇬🇧), Internet Draft draft-adams-qos-broadband-00, IETF, Individual Submission, December 20, 2001, [BibTeX, XML].
Abstract: This document describes a proposal which deals with congestion conditions that may arise when a home or SME customer requests too many simultaneous flows to be forwarded down a DSL link or other access technology. It provides a solution to guaranteeing certain flows while making others (typically the latest or another flow selected for policy reasons) the subject of focused packet discards. It has a number of significant benefits over other possible solutions, such as classical RSVP, and these are also listed in the document.
URL: https://www.ietf.org/archive/id/draft-adams-qos-broadband-00.txt
MD5: bc1aa9e7e0a060b9806b73155ec8f46e
Currently, our QoS protocol has not yet been implemented. Our plan is to implement the device's functionality as a Queuing Discipline (QDisc) for Linux Traffic Control. This implementation is offered as a student project.