
AI Accelerators

Programming Adaptive Embedded Systems
With the rise of the Internet of Things (IoT) and Machine Learning, we are observing a continuous increase in performance requirements for embedded and battery-powered devices. To meet these demands, new hardware and software concepts are needed—ones that are both highly energy-efficient and powerful. However, as system requirements can change over time, devices should be capable of adapting by swapping out hardware accelerators according to current needs, ensuring optimal performance for any given situation.
One example of such a hardware component is the Field Programmable Gate Array (FPGA). FPGAs are distinguished by their ability to instantiate various highly specialized hardware accelerators and switch between them based on application requirements. However, their use in embedded scenarios remains experimental. The greatest challenge lies in the significantly more complex application development process for FPGAs.
To simplify this, we have developed the Elastic Node platform, consisting of both the hardware platform and the software suite.
Contacts: Dr.-Ing. Andreas Ersblöh, Chao Qian, M.Sc., David Peter Federl, M.Sc.
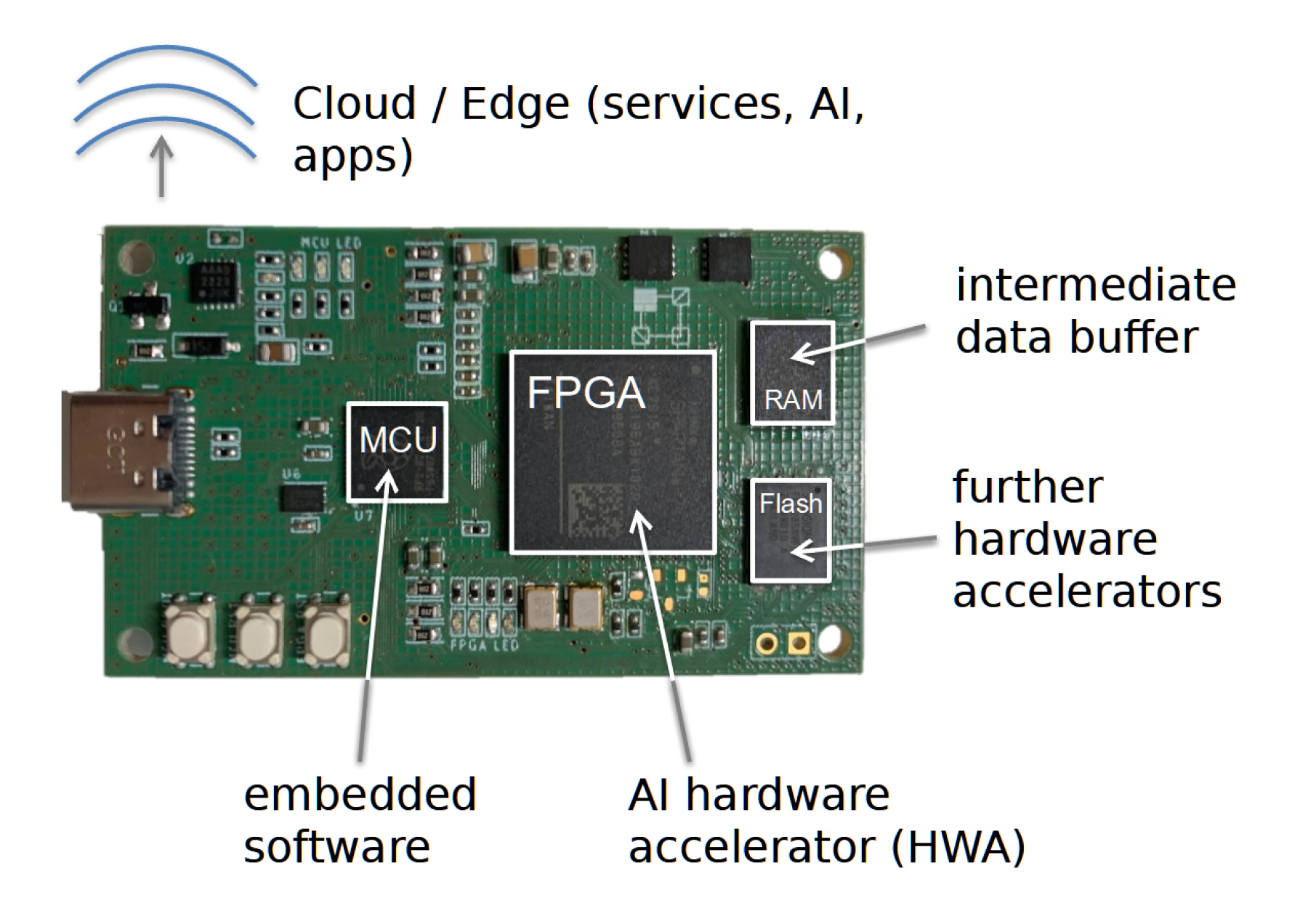
Hybrid hardware platforms with AI acceleration
Consequently, part of our research consists of designing and implementing specialised hardware in the form of AI hardware accelerators. For this purpose, we use flexible FPGAs that allow us to implement arbitrary AI models on hardware in a cheap and efficient way.
The hybrid hardware platform Elastic Node, which is part of the Elastic AI ecosystem, can be cons
idered as both the fruit and instrument of our research and is designed to meet demands for usability, adaptability and monitorability, while at the same time being efficient.
For this reason, we are also investigating adequate hardware-related optimisation options for this particular area. After all, precise knowledge of the hardware allows us to find many different approaches that can be used to fully utilise the available resources. For example, there are potential savings by implementing individual model layers with quantized activation functions by means of LUTs. Other examples would be not activating certain model layers at every clock cycle, parallelisation in the ALU and many other approaches.
Contact: Chao Qian, M.Sc.