
Embedded Artificial Intelligence

Artificial intelligence enables the efficient processing of high-dimensional data and thereby opens up a wide range of new application areas. Current research particularly focuses on deploying deep neural networks, such as convolutional neural networks, on embedded and resource-constrained systems. Despite their traditionally high resource demands, AI technologies are increasingly being used in small, mobile, and even wearable devices. This development is driven by specialized hardware, efficient optimizations, and automated tools and templates that significantly reduce energy and resource consumption while lowering the barriers to practical adoption.
Optimizations for Neural Networks
Our research focuses on optimizing AI models, particularly deep learning (DL) architectures, for deployment on resource-constrained IoT devices such as embedded FPGAs. The focus is especially on the quantization of neural networks, i.e. the reduction of numerical precision of model parameters to decrease memory usage and computational load, as well as on the use of transformer models.
 In this context, we generally investigate optimizations for the training of networks while striving for the quickest and most efficient computations possible, for instance, through the use of separable convolutions.
In this context, we generally investigate optimizations for the training of networks while striving for the quickest and most efficient computations possible, for instance, through the use of separable convolutions.
In addition, in quantised neural networks (QNN), a low bit depth of two or fewer bits, in conjunction with the properties of FPGAs, allows operations within the network to be pre-computed to be stored in the LUTs of the configurable logic blocks for the shortest possible access time.
Contact: Lukas Einhaus, M.Sc.
Our research focuses on energy-efficient time-series analysis on resource-constrained embedded FPGAs. We work on quantization and hardware-aware deployment of deep neural networks (especially Transformers) on embedded FPGAs. Our work covers forecasting, classification, and anomaly detection, with comparative studies involving LSTM models, 1D-CNN models and other hybrid architectures. Key methods include multi-objective optimization and mixed-precision quantization to balance accuracy, latency, and energy use, supported by an automated deployment framework across different FPGA platforms.
Our automated toolchain, ElasticAI.creator, is used for model development and deployment. The goal of the research is to create a balance between model accuracy and hardware-related consumption (such as latency, energy). These findings are applied in our research project RIWWER.
Contact: Tianheng Ling, M.Sc.
Hardware-aware neural architecture search
Finding the ideal neural architecture for a particular use case can take a lot of time and trial and error.
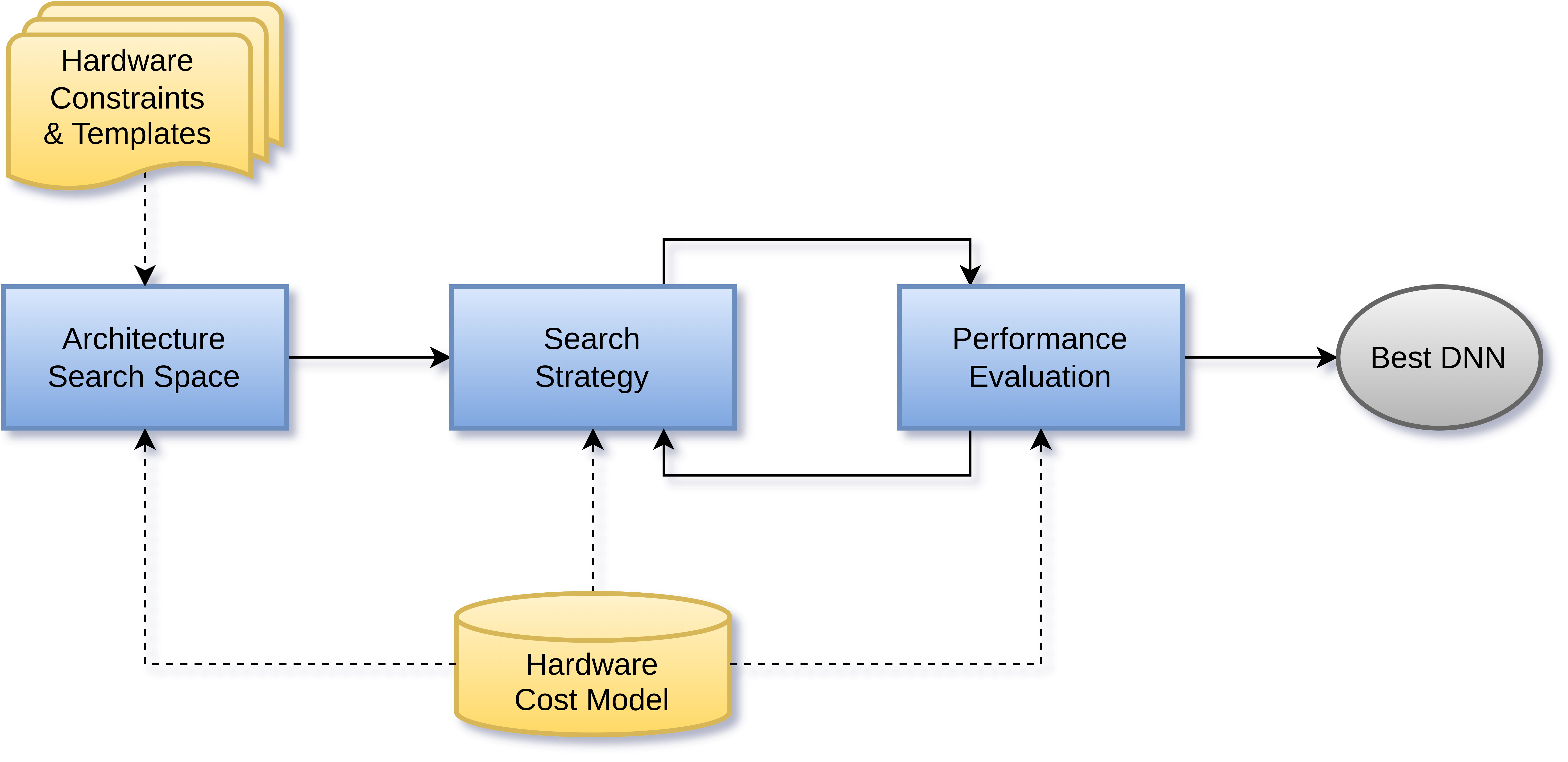
Neural Architecture Search (NAS for short) automates this design step and even finds architectures that outperform those created manually in some cases. Furthermore, even the required resource estimation can be automated by a Deep Neural Network. In this way, the tailored deployment of neural networks is simplified greatly.
{kind=link}
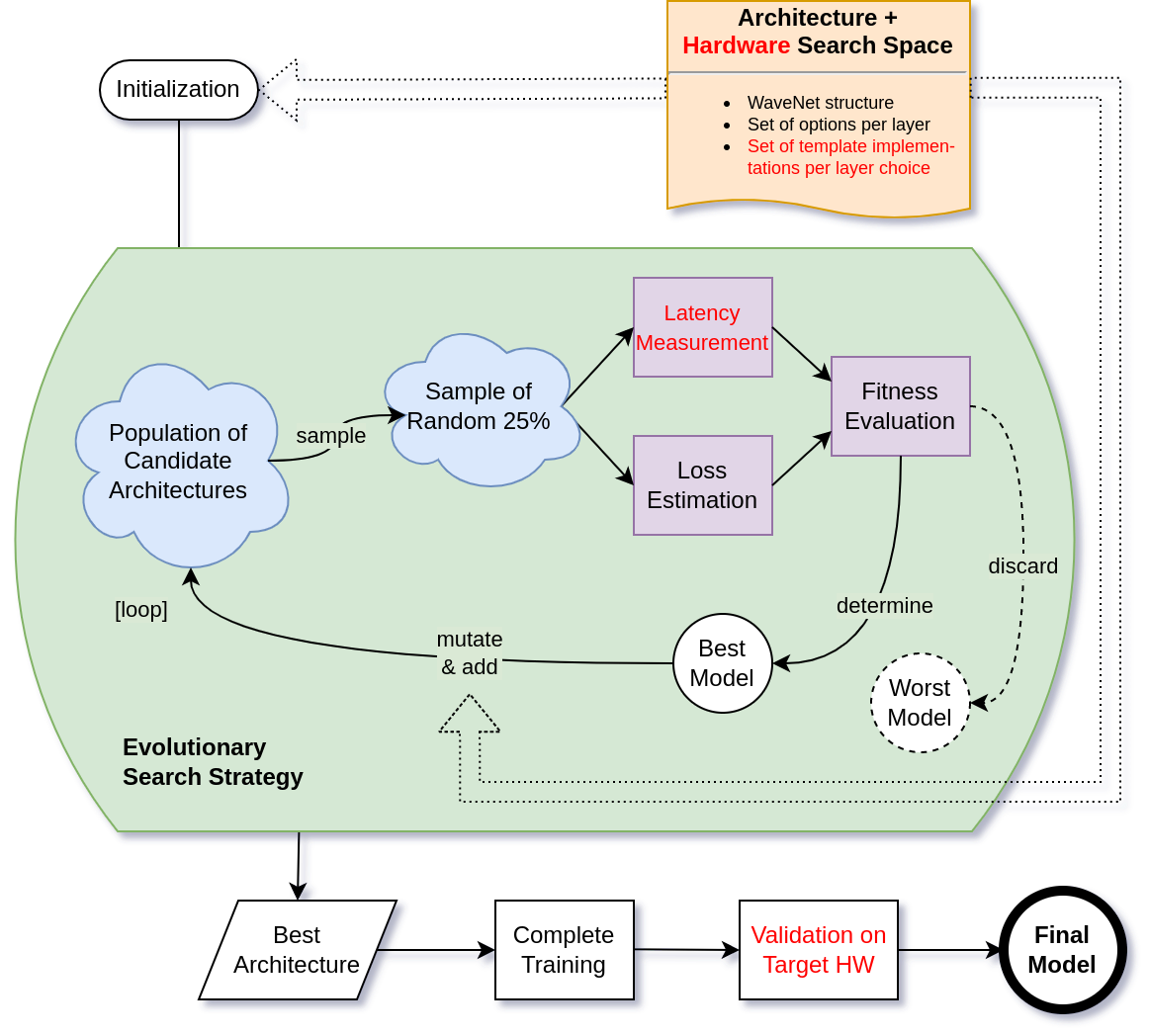
The method, which we currently focus on, is based on the combination of evolutionary algorithms and reinforcement learning and discovers optimal architectures by deliberately mutating, recombining and weeding out contenders. Our requirements typically include efficient operation on resource-constrained hardware, hence hardware costs such as latency or energy consumption are included as optimisation criteria in the architecture search.
Our ongoing studies once again focus on applications in the domains of signal processing and time series analysis, e.g. to find latency-optimized architectures for the simulation of time-variant non-linear audio effects.
Contact: Christopher Ringhofer, M.Sc.

Building on this work, it is becoming increasingly evident that the performance of neural architectures strongly depends on subsequent compression techniques. In most cases, NAS and compression methods such as quantization are considered in completely independent steps to keep the search space manageable. However, this approach has the drawback that dependencies between the chosen architectural parameters and the effects of the applied
quantization scheme are not taken into account during NAS, which can lead to suboptimal models. Our current research therefore investigates ways to combine both approaches in a meaningful manner, with a particular focus on expanding the search space and refining the evaluation strategy for the sampled models.
Contact: Natalie Maman, M.Sc.
The TransfAIr project plays a key role in translating this research into practical applications. Within the project, the development of the ElasticAI.Explorer toolbox is being advanced. This toolbox is designed to provide tools that enable AI models to be executed on various embedded systems and to be automatically optimized for them through HW-NAS.
The goal is to facilitate and improve the “TransfAIr” of AI models across diverse hardware environments. Particulary, the focus lies on the deployment on different hardware platforms as well as the extension and enhancement of the software stack.
Contact: Robin Feldmann, M.Sc.
Embedded Kolmogorov-Arnold Networks

A part of our research deals with novel neural network architectures based on the Kolmogorov-Arnold representation theorem. The focus is on Kolmogorov-Arnold Networks (KANs), a promising approach in which the weights of a neural network are replaced by learnable nonlinear functions. This structure enables models that are more interpretable, flexible, and expressive than classical multi-layer perceptrons (MLPs).
As part of our research, we evaluate the areas of application in which the KAN architecture offers a practical advantage and how the resource requirements of KAN models can be reduced, e.g., by applying quantization or the replacement of learned nonlinear functions. Due to the explainability of KAN models, this method can offer advantages in safety-critical areas such as medicine or the automotive sector.
In line with our research, we are developing the KANLib framework . This is a modular and easily extensible KAN implementation for PyTorch. The aim is to evaluate and improve the practical applicability of KANs in embedded systems.
Contact: Julian Hoever, M.Sc.
Memory-Constrained Training of Deep Neural Networks on Microcontrollers
Training deep neural networks is predominantly performed on powerful GPUs or specialized accelerators, while microcontroller-based systems are typically limited to inference. In our research, we challenge this assumption and investigate the direct training of neural networks on microcontrollers under severe memory constraints.
Our focus is on classical Cortex-M systems with only a few hundred kilobytes of RAM, no external memory, and no hardware accelerators for matrix operations. In this setting, training is not compute-bound but memory-bound: activations, gradients, and optimizer states quickly exceed the available resources, making existing training methods and optimization algorithms difficult to transfer. The goal of this research is the systematic analysis and reduction of memory consumption during training. To this end, analytical memory models are developed, and techniques such as quantization, unstructured pruning, sparse updates, and lossy compression are selectively combined and dynamically adapted during training.
A particular focus is placed on quantized parameter updates (QPU). This novel approach enables the training of neural networks directly with quantized parameters and stochastically rounded updates, allowing floating-point weights to be completely eliminated and significantly reducing the memory footprint during training. There is special interest in utilizing the freed-up memory resources to improve convergence speed and final model accuracy, for example through adaptive batch sizes, dynamic bit widths, and the gradual extension of simple optimizers toward more memory-intensive methods.
The proposed methods are evaluated on time-series and image classification tasks and implemented on real MCU hardware. In the long term, this work contributes to autonomous, privacy-preserving, and energy-efficient adaptation of neural networks directly on embedded systems.
Contact: Leo Buron, M.Sc.
Delta Compression
The increasing size of modern neural networks poses significant challenges for embedded systems. Especially in the context of energy-efficient hardware such as FPGAs or microcontrollers, there is a growing need for methods that reduce memory consumption and computational effort without substantially effecting model quality.
One approach explored in our research is delta compression. Instead of storing full model parameters, only deltas are retained. Since Deltas can be compressed with less loss of information, considerable memory savings can be achieved which enables the deployment of larger models in small systems. Delta compression opens up new opportunities for using AI models in embedded environments. It provides an alternative to heavily quantized or structurally reduced network architectures and allows more complex models to operate in resource-constrained settings. At the same time, the compression process almost inevitably introduces information loss, which may impact model performance. Developing suitable methods for error mitigation and adaptive compression strategies is therefore a central topic of ongoing research.
In the long term, delta compression will be combined with additional optimization techniques such as structural pruning or quantization-aware training to enable AI models that are both robust and resource-efficient.
Contact: David Peter Federl, M.Sc.
Towards smart surfaces

In our research, we focus on the development of smart surfaces, in which everyday surfaces such as tables are used as interactive interfaces for smart home applications. Instead of relying on additional input devices or visible technology, existing surfaces are augmented through seamlessly integrated sensors and local signal processing.
The approach is based on capturing vibrations generated by gestures such as tapping or knocking on the surface. These vibration signals are acquired by the sensors and are analyzed directly on the device using machine learning methods. By relying exclusively on on-device processing, a privacy-by-design approach is pursued that operates without cameras, microphones, or cloud connectivity. Building on existing work such as Smatable, a complete end-to-end system is being developed that combines hardware, signal processing, and energy-efficient AI models. The focus is on compact 1D CNN architectures that are suitable for deployment on embedded and FPGA platforms.
In future research, we investigate the expansion of the gesture vocabulary, the localization of gestures on individual surfaces, and the transferability to different materials and usage scenarios. The goal is to enable natural, robust, and privacy-friendly interactions with smart everyday surfaces.
Contact: Florian Hettstedt, M.Sc.
Deep Reinforcement Learning
Deep Reinforcement Learning (DRL) has established itself as a powerful approach for complex decision-making and control problems. Despite its considerable empirical success, fundamental theoretical challenges remain at the interface of Deep Learning (DL) and Reinforcement Learning (RL), which are the focus of this research.
A central theoretical issue in Reinforcement Learning is the so-called deadly triad: the combination of function approximation, bootstrapping, and off-policy learning, which can lead to divergence of the model parameters. Using an eigenvalue analysis of classical counterexamples, we investigate the underlying update matrices. We show that, in the counterexamples considered, the matrix governing the parameter updates possesses at least one positive eigenvalue. This provides a theoretical explanation for why DRL methods often converge stably in practice: for certain problem settings, suitable function approximations exist under which stable parameter updates are possible.
A further focus of our work is the IID assumption, a fundamental prerequisite for the use of stochastic gradient-based optimization methods in Deep Learning. In Reinforcement Learning, however, this assumption is violated, as training data is generated through sequential interaction and is neither independent nor stationary. Our research demonstrates that the success of modern DRL algorithms relies heavily on techniques such as experience replay and target networks, which deliberately alter the data structure. In this way, our work contributes to a deeper understanding of how deep learning methods can be adapted to the specific requirements of experience-based learning.
Contact: Fatih Özgan, M.Sc.