
Eingebettete künstliche Intelligenz

Künstliche Intelligenz ermöglicht die performante Verarbeitung hochdimensionaler Daten und eröffnet dadurch vielfältige neue Einsatzgebiete. Aktuelle Forschung untersucht insbesondere den Einsatz tiefer neuronaler Netze, wie etwa Convolutional Neural Networks, auf eingebetteten und ressourcenbeschränkten Systemen. Trotz ihres traditionell hohen Ressourcenbedarfs finden KI-Technologien zunehmend Anwendung in kleinen, mobilen und sogar tragbaren Geräten. Möglich wird dies durch spezialisierte Hardware, effiziente Optimierungen sowie automatisierte Werkzeuge und Vorlagen, die den Energie- und Ressourcenverbrauch deutlich reduzieren und den praktischen Einsatz erleichtern.
Optimierung von Neuronalen Netzwerken
In unserer Forschung fokussieren wir uns auf die Optimierung von KI-Modellen, insbesondere Deep Learning (DL)-Architekturen, für den Einsatz auf ressourcenbeschränkten IoT-Geräten, wie eingebetteten FPGAs. Hier liegt der Fokus besonders auf der Quantisierung neuronaler Netzwerke, also der Reduzierung der numerischen Präzision von Modellparametern, um Speicherbedarf und Rechenintensität zu verringern und auf der Nutzung von Transformer-Modellen.

Dabei untersuchen wir allgemein Optimierungen beim Training der Netzwerke und streben möglichst schnelle wie effiziente Berechnungen an, beispielweise durch den Einsatz separierbarer Faltungen.
Zudem erlaubt es bei quantisierten neuronalen Netzwerken (QNN) eine geringe Bittiefe von zwei oder weniger Bit im Zusammenspiel mit der Beschaffenheit von FPGAs, Operationen innerhalb des Netzwerkes vorauszuberechnen und die entsprechenden Ergebnisse für schnellstmöglichen Zugriff in den LUTs der konfigurierbaren Logikblöcke zu hinterlegen.
Ansprechpartner: Lukas Einhaus, M.Sc.
Unsere Forschung konzentriert sich auf energieeffiziente Zeitreihenanalysen auf eingebetteten FPGAs mit begrenzten Ressourcen. Wir arbeiten an der Quantisierung und hardwarebewussten Bereitstellung tiefer neuronaler Netze (insbesondere Transformatoren) auf eingebetteten FPGAs. Unsere Arbeit umfasst Prognosen, Klassifizierungen und Anomalieerkennung mit Vergleichsstudien zu LSTM-Modellen, 1D-CNN-Modellen und anderen hybriden Architekturen. Zu den wichtigsten Methoden gehören die multikriterielle Optimierung und die Quantisierung mit gemischter Genauigkeit, um Genauigkeit, Latenz und Energieverbrauch in Einklang zu bringen, unterstützt durch ein automatisiertes Bereitstellungsframework für verschiedene FPGA-Plattformen.
Unsere automatisierte Toolchain ElasticAI.creator wird für die Modellentwicklung und -bereitstellung verwendet. Das Ziel der Forschung ist es, ein Gleichgewicht zwischen Modellgenauigkeit und hardwarebezogenem Verbrauch (wie Latenz, Energie) herzustellen. Diese Erkenntnisse werden in unserem Forschungsprojekt RIWWER angewendet.
Ansprechpartnerin: Tianheng Ling, M.Sc.
Hardwaresensitive Neuronale Architektursuche
Die ideale neuronale Architektur für den jeweiligen Anwendungsfall zu finden, kann viel Zeit und Ausprobieren erfordern.
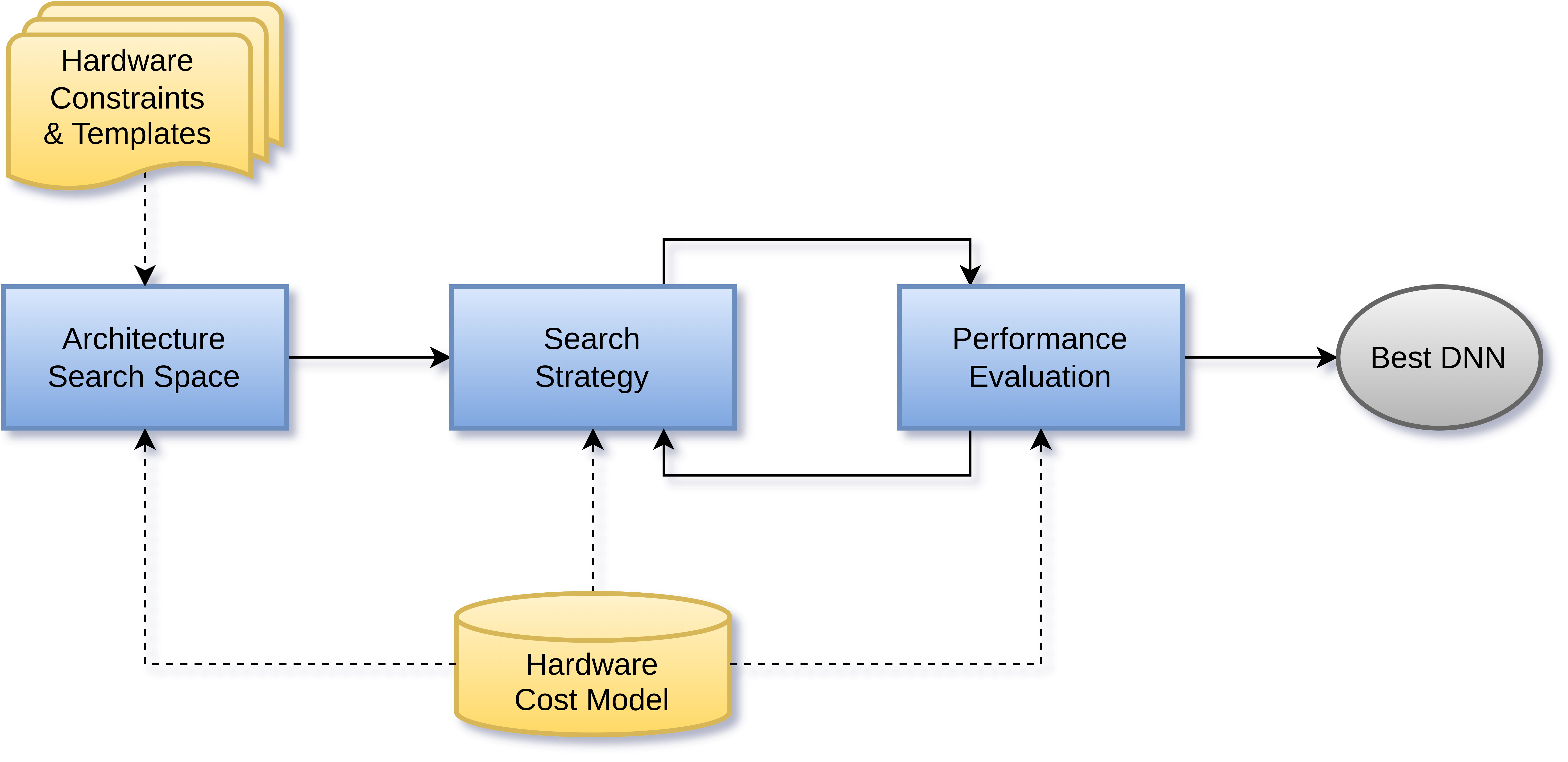
Die Neuronale Architektursuche (auch NAS) automatisiert diesen Gestaltungsschritt und findet teilweise Architekturen, die manuell erstellte übertreffen. Ferner lässt sich sogar die nötige Ressourcenabschätzung durch ein Tiefes Neuronales Netzwerk automatisieren. Auf diese Weise wird der bedarfsangepasste Einsatz von Neuronalen Netzwerken wesentlich vereinfacht.
{kind=link}
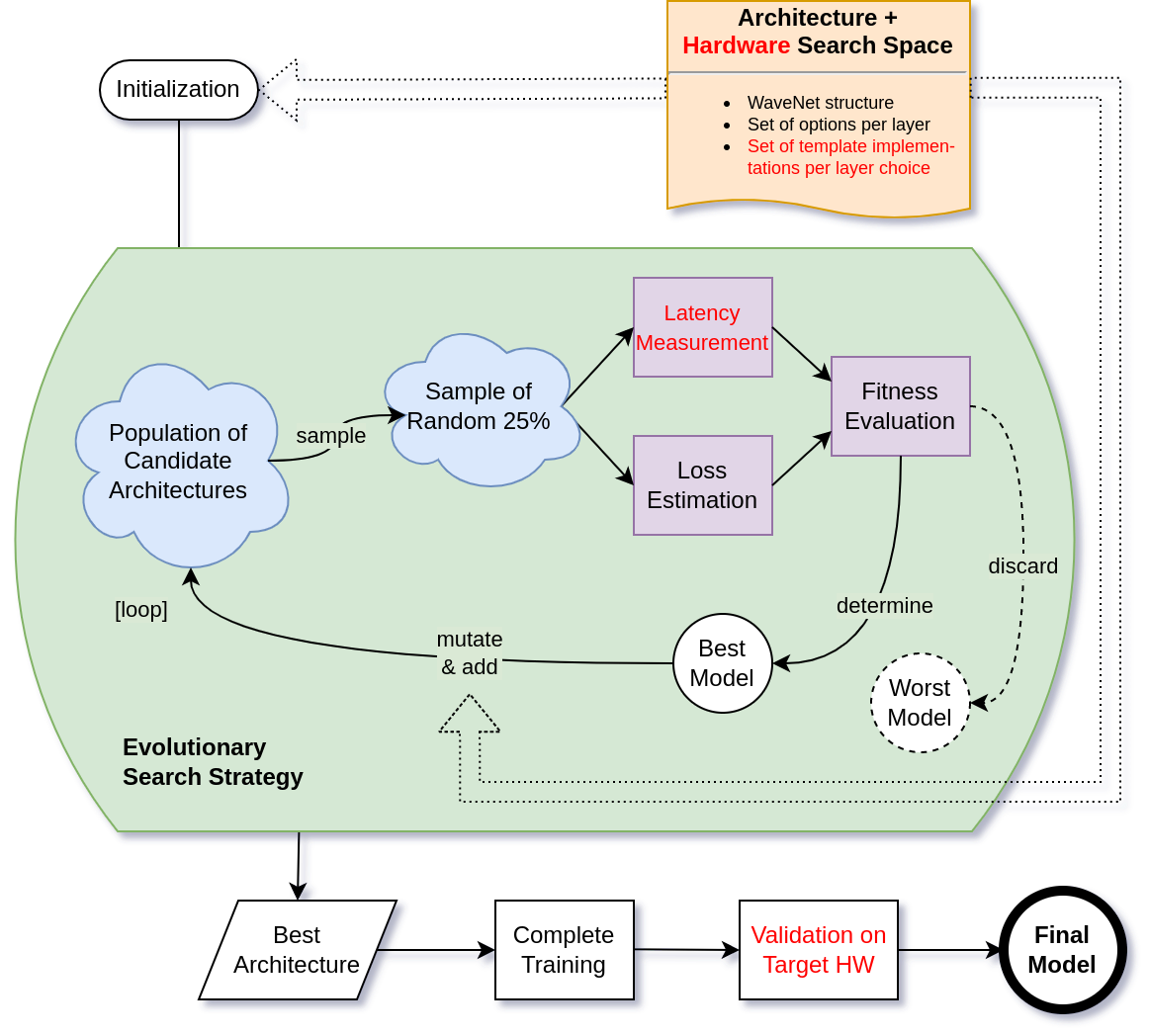
Das Verfahren, auf dem zur Zeit unser Hauptaugenmerk liegt, beruht auf der Kombination von evolutionären Algorithmen und Reinforcement Learning und findet optimale Architekturen durch zielgerichtetes Mutieren, Rekombinieren und Aussortieren von Kandidaten. Unsere Anforderungen beinhalten typischerweise den effizienten Betrieb auf ressourcenbeschränkter Hardware, darum fließen Hardwarekosten wie Latenz oder Energieverbrauch als Optimierungskriterien in die Architektursuche mit ein.
Unsere Forschung fokussiert sich hierbei abermals auf Anwendungsfälle aus den Bereichen Signalverarbeitung und Zeitreihenanalyse, beispielsweise um latenzoptimierte Architekturen für die Simulation von zeitvarianten, nicht-linearen Audioeffekten zu finden.
Ansprechpartner: Christopher Ringhofer, M.Sc.

Aufbauend auf diesen Arbeiten zeigt sich zunehmend, dass die Leistungsfähigkeit neuronaler Architekturen stark von nachgelagerten Komprimierungsverfahren abhängt. Meist werden die NAS und Komprimierungsverfahren wie Quantisierung in komplett voneinander unabhängigen Schritten betrachtet, um den Suchraum überschaulicher zu gestalten. Dieses Vorgehen hat aber den Nachteil, dass Abhängigkeiten zwischen den gewählten Architekturparametern und dem Einfluss des gew
ählten Quantisierungsschemas in der NAS nicht mit betrachtet werden, was zu suboptimalen Modellen führen kann. Unsere Forschung untersucht aktuell Möglichkeiten beide Verfahren sinnvoll zu kombinieren, mit einem Hauptaugenmerk auf die Suchraumerweiterung und die Evaluationsstrategie der gesampleten Modelle.
Ansprechpartnerin: Natalie Maman, M.Sc.
Eine zentrale Rolle bei der praktischen Umsetzung dieser Forschung spielt das Projekt TransfAIr, in dessen Rahmen die Entwicklung der Toolbox ElasticAI.Explorer vorangetrieben wird. Diese soll Werkzeuge bereitstellen, um KI-Modelle auf unterschiedlichen eingebetteten System ausführen zu können und automatisiert über HW-NAS dafür zu optimieren. Ziel ist es, den „TransfAIr“ von KI-Modellen auf diverse Hardwareumgebungen zu erleichtern und zu optimieren. Der Fokus liegt dabei insbesondere auf dem Deployment auf unterschiedlichen Hardware-Plattformen sowie auf der Erweiterung und Verbesserung des Software-Stacks.
Ansprechpartner: Robin Feldmann, M.Sc.
Embedded Kolmogorov-Arnold Networks

Ein Teil unserer Forschung beschäftigt sich mit neuartigen neuronalen Netzwerkarchitekturen, die auf dem Kolmogorov-Arnold-Repräsentationstheorem basieren. Dabei liegt der Fokus auf Kolmogorov-Arnold Networks (KANs), einem vielversprechenden Ansatz, bei dem die Gewichte eines neuronalen Netzes durch lernbare nichtlineare Funktionen ersetzt werden. Diese Struktur ermöglicht Modelle, die gleichzeitig interpretierbarer, flexibler und ausdrucksstärker sind als klassische Multi-Layer-Perceptrons (MLPs).
Im Rahmen der Forschung evaluieren wir in welchen Anwendungsgebieten die KANs Architektur einen praktischen Vorteil bietet und wie sich der Ressourcenbedarf der KAN-Modelle reduzieren lässt, z.B. durch Anwendung von Quantisierung oder durch Ersetzen von gelernten nicht-linearen Funktionen. Aufgrund der Erklärbarkeit der KAN-Modelle, kann diese Methode besondere Vorteile in sicherheitskritischen Bereichen, wie der Medizin oder im Automotive Sektor bieten.
Im Rahmen der Forschung wird das KANLib-Framework entwickelt. Dabei handelt es sich um eine modulare und einfach erweiterbare KAN-Implementierung für PyTorch. Ziel ist es, die praktische Einsetzbarkeit von KANs in eingebetteten Systemen zu evaluieren und zu verbessern.
Ansprechpartner: Julian Hoever, M.Sc.
Speicherbeschränktes Training tiefer neuronaler Netze auf Mikrocontrollern
Das Training tiefer neuronaler Netze erfolgt überwiegend auf leistungsstarken GPUs oder spezialisierten Beschleunigern, während Microcontroller-basierte Systeme meist auf reine Inferenz beschränkt sind. In unserer Forschung stellen wir diese Annahme in Frage und untersuchen das direkte Training neuronaler Netze auf Microcontrollern unter extremen Speicherbeschränkungen.
Im Fokus stehen klassische Cortex-M-Systeme mit wenigen hundert Kilobyte RAM, ohne externe Speicher und ohne Hardwarebeschleuniger für Matrixoperationen. In diesem Szenario ist das Training nicht rechen-, sondern speicherlimitiert: Aktivierungen, Gradienten und Optimizer-Zustände übersteigen schnell die verfügbaren Ressourcen, sodass bestehende Trainingsmethoden und Optimierungsalgorithmen nicht ohne Weiteres übertragbar sind. Ziel unserer Forschung ist die systematische Analyse und Reduktion des Speicherverbrauchs während des Trainings. Hierzu werden analytische Speichermodelle entwickelt und darauf aufbauend Techniken wie Quantisierung, unstrukturiertes Pruning, spärliche Updates und verlustbehaftete Kompression gezielt kombiniert und dynamisch angepasst.
Ein konkreter Schwerpunkt liegt dabei auf quantisierten Parameter-Updates (QPU). Es handelt sich um einen neuen Ansatz, der das Training neuronaler Netze direkt mit quantisierten Parametern und stochastisch gerundeten Updates ermöglicht, sodass vollständig auf Floating-Point-Gewichte verzichtet werden kann und der Speicherbedarf während des Trainings deutlich reduziert wird. Ein besonderes Interesse besteht daraufhin an der Nutzung der freigewordenen Speicherressourcen zur Verbesserung von Konvergenzgeschwindigkeit und Modellgenauigkeit, etwa durch adaptive Batch-Größen, dynamische Bitbreiten und die schrittweise Erweiterung einfacher Optimierer.
Die entwickelten Methoden werden auf Zeitreihen- und Bildklassifikationsaufgaben evaluiert und auf realer MCU-Hardware implementiert. Langfristig leistet diese Arbeit einen Beitrag zur autonomen, datenschutzfreundlichen und energieeffizienten Anpassung neuronaler Netze auf eingebetteten Systemen.
Ansprechpartner: Leo Buron, M.Sc.
Delta-Kompression
Die zunehmende Größe moderner neuronaler Netze stellt eingebettete Systeme vor erhebliche Herausforderungen. Insbesondere im Kontext energieeffizienter Hardware wie FPGAs oder Mikrocontrollern besteht ein wachsender Bedarf an Verfahren, die Speicherbedarf und Rechenaufwand reduzieren, ohne dabei die Modellqualität wesentlich zu beeinträchtigen.
Ein Ansatz, mit dem sich unsere Forschung beschäftigt, ist die Delta-Kompression. Bei diesem Verfahren werden anstelle vollständiger Modelparameter, lediglich Deltas gespeichert. Da diese mit einem geringeren Informationsverlust komprimiert werden können, entstehen deutliche Einsparungen an Speicherplatz, was den Einsatz größerer Modelle auf kleinen Systemen ermöglicht. Die Delta-Kompression eröffnet neue Möglichkeiten für den Einsatz von KI-Modellen in eingebetteten Anwendungen. Sie bietet eine Alternative zu stark quantisierten oder strukturell reduzierten Netzarchitekturen und erlaubt es, Modelle mit höherer Komplexität in ressourcenarmen Umgebungen auszuführen. Gleichzeitig führt die Kompression fast zwangsläufig zu Informationsverlusten, die sich auf die Modellperformance auswirken können. Die Entwicklung geeigneter Methoden zur Fehlerbegrenzung und adaptiven Kompressionsstrategien ist daher ein zentraler Bestandteil aktueller Forschung.
Langfristig soll die Methode mit weiteren Optimierungstechniken wie strukturellem Pruning oder quantisierungsbewusstem Training kombiniert werden, um robuste und zugleich ressourceneffiziente KI-Modelle bereitzustellen.
Ansprechpartner: David Peter Federl, M.Sc.
Smart Surfaces

In unserer Forschung beschäftigen wir uns mit der Entwicklung von Smart Surfaces, bei denen alltägliche Oberflächen wie Tische als interaktive Schnittstellen für Smart-Home-Anwendungen genutzt werden. Anstelle zusätzlicher Eingabegeräte oder sichtbarer Technik sollen bestehende Oberflächen durch nahtlos integrierte Sensorik und lokale Signalverarbeitung erweitert werden.
Der Ansatz basiert auf der Erfassung von Vibrationen, die durch Gesten wie Tippen oder Klopfen auf der Oberfläche entstehen. Diese Schwingungssignale werden von unauffällig integrierten Sensoren erfasst und mithilfe maschineller Lernverfahren direkt auf dem Gerät ausgewertet. Durch die ausschließliche On-Device-Verarbeitung wird ein Privacy-by-Design-Ansatz verfolgt, der ohne Kameras, Mikrofone oder Cloud-Anbindung auskommt. Aufbauend auf bestehenden Arbeiten wie Smatable wird ein vollständiges End-to-End-System entwickelt, das Hardware, Signalaufbereitung und energieeffiziente KI-Modelle kombiniert. Der Fokus liegt dabei auf kompakten 1D-CNN-Architekturen, die für den Einsatz auf Embedded- und FPGA-Plattformen geeignet sind.
In zukünftiger Forschung untersuchen wir die Erweiterung des Gestenvokabulars, die Lokalisierung von Gesten auf einzelnen Oberflächen sowie die Übertragbarkeit auf unterschiedliche Materialien und Nutzungsszenarien. Ziel ist es, natürliche, robuste und datenschutzfreundliche Interaktionen mit smarten Alltagsoberflächen zu ermöglichen.
Ansprechpartner: Florian Hettstedt, M.Sc.
Deep Reinforcement Learning
Deep Reinforcement Learning (DRL) hat sich als leistungsfähiger Ansatz für komplexe Entscheidungs- und Steuerungsprobleme etabliert. Trotz beachtlicher empirischer Erfolge bestehen jedoch grundlegende theoretische Herausforderungen an der Schnittstelle von Deep Learning (DL) und Reinforcement Learning (RL), denen sich unsere Forschung widmet.
Ein zentrales Problem des Reinforcement Learning ist die sogenannte Deadly Triad: die Kombination aus Funktionsapproximation, Bootstrapping und Off-Policy-Lernen, die zur Divergenz der Modellparameter führen kann. Mithilfe einer Eigenwertanalyse klassischer Gegenbeispiele untersuchen wir die zugrunde liegenden Update-Matrizen. Dabei konnten wir zeigen, dass die für die Parameteraktualisierung entscheidende Matrix in den untersuchten Gegenbeispielen mindestens einen positiven Eigenwert besitzt. Dies liefert eine theoretische Erklärung dafür, warum DRL-Verfahren in der Praxis häufig stabil konvergieren, da für bestimmte Problemstellungen geeignete Funktionsapproximationen existieren, unter denen stabile Updates möglich sind.
Ein weiterer Schwerpunkt liegt auf der IID-Annahme, einer Grundvoraussetzung für den Einsatz stochastischer Gradientenverfahren im Deep Learning. Im Reinforcement Learning ist diese Annahme jedoch verletzt, da Trainingsdaten durch sequentielle Interaktion entstehen und nicht unabhängig sowie nicht stationär sind. Mit unserer Forschung konnten wir zeigen, dass der Erfolg moderner DRL-Algorithmen maßgeblich auf Verfahren wie Experience Replay oder Target Networks beruht, die die Datenstruktur gezielt verändern. Damit trägt unsere Forschung zu einem besseren Verständnis bei, wie Deep-Learning-Methoden an die spezifischen Anforderungen des bestärkenden Lernens angepasst werden können.
Ansprechpartner: Fatih Özgan, M.Sc.